


I thought I take this moment to help people decipher what really goes behind Spidermon, and how it works. Since my mentors helped me understand it, I think its only right for me to pass on this knowledge.
Let’s start …
Source code is available here for your reference, since we would be referring it alot https://github.com/scrapinghub/spidermon/
I will be going with a brief overview of how Scrapy, the spiders and spidermon works together. This would need an understanding of the directory structure and code of Scrapy as well as basic know-how of what Spidermon is. Spidermon is a framework to build monitors for Scrapy spiders. It offers the following features:
- It can check the output data produced by Scrapy (or other sources) and verify it against a schema or model that defines the expected structure, data types, and value restrictions. (This is what I work on)
- It allows you to define conditions that should trigger an alert based on Scrapy stats.
- It supports notifications via email and Slack. (Also, this)
- It can generate custom reports. (And this)
Well, let’s say we built a spider, let’s call it our famous quotes spider that Scrapy’s docs site uses to teach people how to scrape with Scrapy. Here’s the code for the actual spider we make in the Spidermon’s Getting Started.
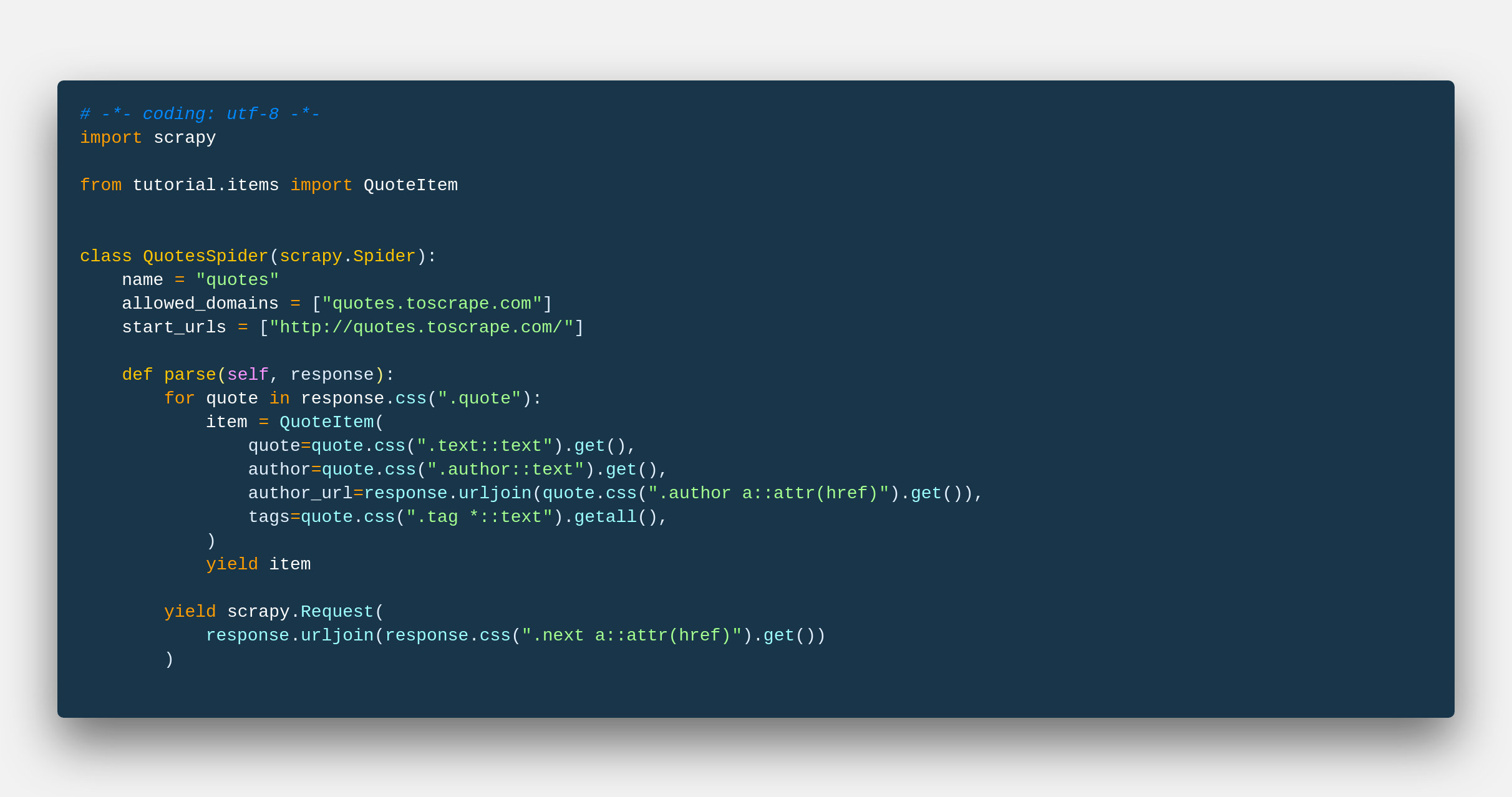
Pretty basic, right. From the parse() method, we are scraping data of quote, author, author_url, and tags. Now, if we could have some system that could validate this data on the fly. Along with that, let me know the errors that comes, wherever I want it and be able to work efficiently.
The real idea here is not validating or monitoring the data of 10 or 50 spiders. Spidermon is built for when you have thousands of spiders deployed and troubleshooting and monitoring is a major pain for the developer. This process could be automated and that’s where Spidermon comes in. Coming back to our code.
If you follow through with the tutorial, then you see we are activating Spidermon through settings.py in our Scrapy Project. Now, that validation we are using here is Schematics. Scroll down a bit, and you see how the monitors work. They inform about the status of our actions. After that’s done, this is how the settings.py would be looking for your Spider.

The integer next to Item_pipelines dict is the priority, where it’s determined when the process will run. The ItemValidationPipeline is the one that takes care of our validation, and that’s what we are going to use as well. So let’s head on to our Spidermon package and jump in a bit of pipeline.
Going Deeper into the Spider’s Nest
This is a small tour I curated around Spidermon that helps you understand the code flow and directory better.
The ItemValidationPipeline class stores all instructions and methods to our validators, and hence acts as a bridge and control center for Spidermon. Next, if you see below we can check the from_crawler method. This chooses which validators will Spidermon be using for validating the data. There are of 2 kinds which are available:-
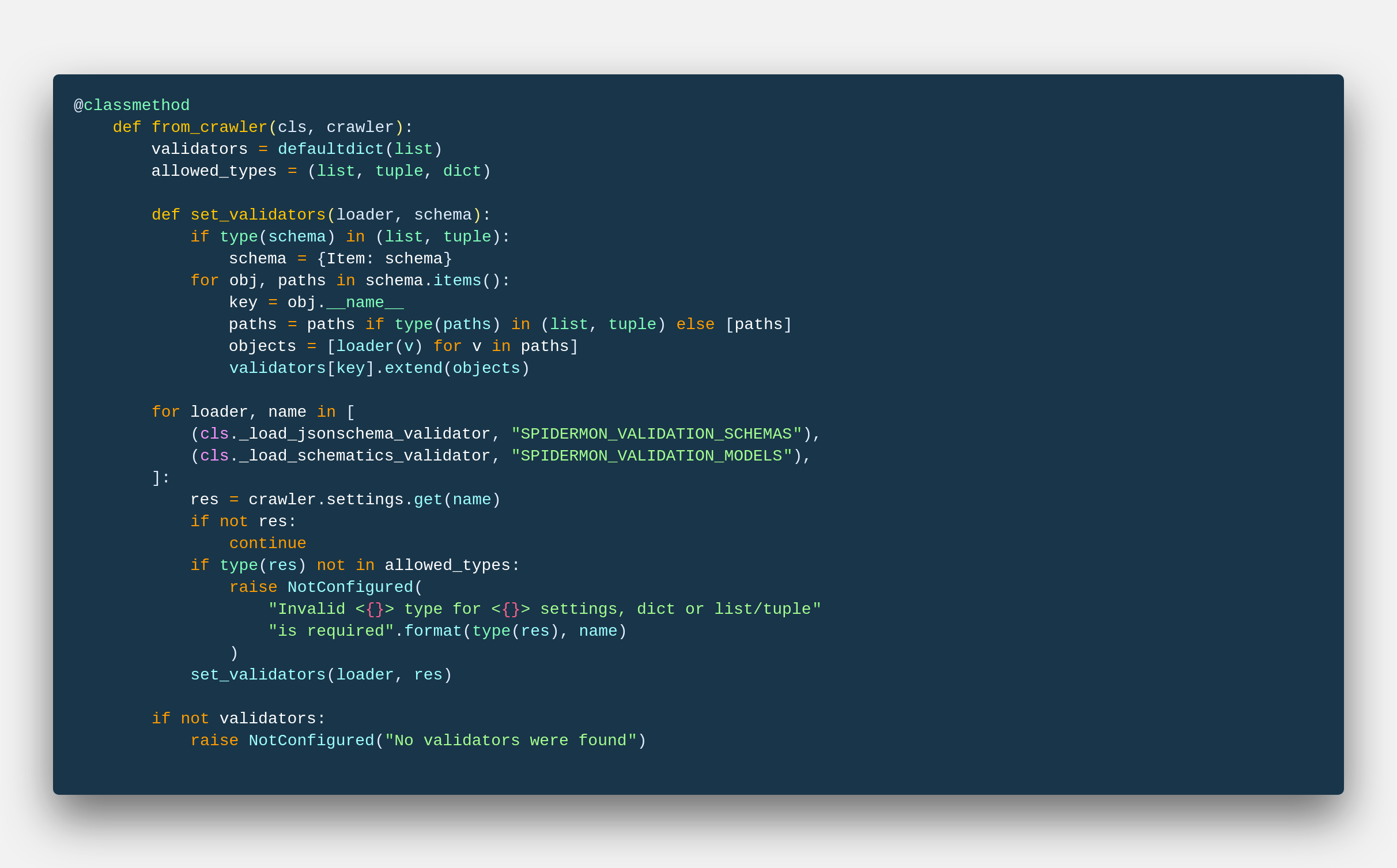
- JSONSchema – JSON Schema is a vocabulary that allows you to annotate and validate JSON documents. But, here we use JSON schemas to validate our data (Which is technically a schema), making the process extremely lightweight, functional and quite powerful in terms of customization and refactoring.

- Schematics – Schematics is a Python library to combine types into structures, validate them, and transform the shapes of your data based on simple descriptions. True Pythonistas would love this, as everything from Schemas to validation rules is written in Python. You can use all the power Python has to play with the rules on the go.

- Cerberus – That’s a new pipeline that I am currently working on. It’s quite powerful, very effective, compatible and through it, I am learning a lot of new things.
That’s about it, now you are familiar with all the validation methods of Spidermon, let’s look at some more code of how the data processing happens. process_item searches for valid validators that from_crawler for us by parsing settings.py. Say, we want Schematics to be used for validating our data. We add Schematics model in settings.py, at the time of execution (crawling), this model that we have and the data that the process_item method would give to the validate() method of Schematics will do the actual data validation. Each pipeline has its own way to translate messages into a more uniform text that we at Spidermon uses.

I think I am just bragging about methods with if statements and calling it the brain. But, I like it.
Lastly, the spider finishes execution or goes for another run as per the code. Do remember that Spidermon is the last task that it runs just before pipelines take over to take the data into a database or output it into a JSON file. Whatever it is. The errors encountered in the data or dealt with as the client needs it to be. Through custom monitors, on the slack channel, through emails and much more notification that Spidermon offers.
So, Validation has been completed. What next?
Part of the journey is the end.
It’s truly up to you where would you like to take it next. Validation is just one of the key ways Spidermon can make the process of scraping more automated, more efficient and much more manageable. Build custom pipelines to take care of errors that pop up in your data. Build custom monitors that detect exceptions and take control of the data flow. There is so much more that could be done with Spidermon.
Well, that’s about it from my side. This has been one of the few posts where I dug into code this much. If I may speak honestly, I loved it. This is a few weeks of study and research that I did with the help of my mentors Julio and Renne. I am not sure without them this would have been possible. Let me know if you like to know more, read more. I would surely love to write about Spidermon Actions.
Hope this helps someone searching about it, in the distant future. I would have loved to find this earlier. That’s all, live in the mix, guys.
0 Comments